Фильтр ключевых слов по вхождению с помощью Python
Написал код для быстрой фильтрации списка фраз прямо из буфера обмена.
В процессе создания списка ключевых фраз под рекламные кампании в Директ или Google Ads периодически требуется фильтровать группы слов для дальнейшей группировки под отдельные кампании. С изучением языка Python я придумал как ускорить работу.
Для собственной реализации я написал скрипт с использованием библиотеки pyperclip, позволяющей тянуть информацию прямо из памяти компьютера.
Схема работы следующая:
1) Я работаю с ключевыми словами. Возникает потребность найти в общем количестве запросы с определенным вхождением фразы. Например «производство».

2) Я копирую список фраз и через командную строку запускаю программу. Она считывает из памяти список, уменьшает все символы и запрашивает искомое слово. По нему происходит фильтрация на поиск совпадений и выдается результат с количеством и самим списком. Специально вывожу фразы не в [списке], для более удобного копирования.
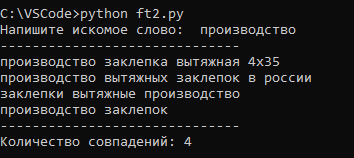
3) После этого я просто копирую список и использую его по назначению.
Код программы
import pyperclip
s = pyperclip.paste().split('\r\n')
# при копировании из notepad разделять нужно только по \r
s = pyperclip.paste().split('\r')
result = []
for row in s:
row = row.lower()
result.append(row)
word = input('Напишите искомое слово: ')
print('------------------------------')
result2 = []
for row2 in result:
if word in row2:
result2.append(row2)
print(row2)
print('------------------------------')
print('Количество совпадений: ' + str(len(result2)))
В дальнейшем я планирую улучшить код для фильтрации с помощью нескольких выражений.
Новые правки
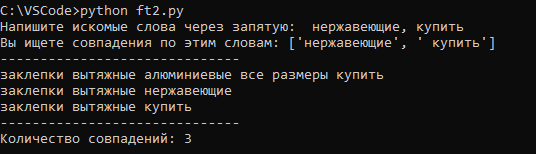
В процессе работы с программой так и пришлось дорабатывать код для фильтра по нескольким запросам. Для этого добавил ввод пользователем неограниченного количества выражений для фильтрации и запись их в список. В последствии по которому идёт отбор фраз.
Результат получается следующим:
import pyperclip
s = pyperclip.paste().split('\r\n')
# при копировании из notepad разделять нужно только по \r
s = pyperclip.paste().split('\r')
result = []
for row in s:
row = row.lower()
result.append(row)
word = input('Напишите искомые слова через запятую: ')
word_list = word.split(',')
print('Вы ищете совпадения по этим словам: ' + str(word_list))
print('------------------------------')
result2 = []
for row2 in result:
for row3 in word_list:
if row3 in row2:
result2.append(row2)
print(row2)
print('------------------------------')
print('Количество совпадений: ' + str(len(result2)))
Минусы
К сожалению код нужно доделывать и ещё раз доделывать. Из очевидного:
— в результат попадают дубли при фильтре по разным вхождениям. Надо убирать их.
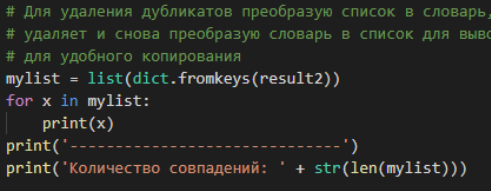
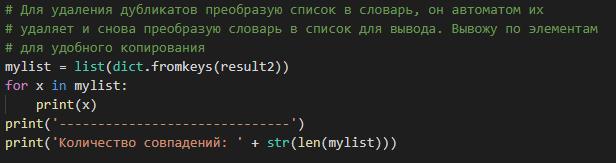
В поздних правках решил эту проблему с помощью перевода списка в словарь — он автоматом удаляет дубликаты, а потом возвратом в список и построчным выводом.
— нет нормализации запросов, приходится вручную вводить все формы слов для фильтрации. Это долго и неправильно.
Общий код:
import pyperclip
s = pyperclip.paste().split('\r\n')
# при копировании из notepad разделять нужно только по \r
s = pyperclip.paste().split('\r')
result = []
for row in s:
row = row.lower()
result.append(row)
word = input('Напишите искомые слова через запятую: ')
word_list = word.split(',')
print('Вы ищете совпадения по этим словам: ' + str(word_list))
print('------------------------------')
result2 = []
for row2 in result:
for row3 in word_list:
if row3 in row2:
result2.append(row2)
#print(row2)
# Для удаления дубликатов преобразую список в словарь, он автоматом их
# удаляет и снова преобразую словарь в список для вывода. Вывожу по элементам
# для удобного копирования
mylist = list(dict.fromkeys(result2))
for x in mylist:
print(x)
print('------------------------------')
print('Количество совпадений: ' + str(len(mylist)))