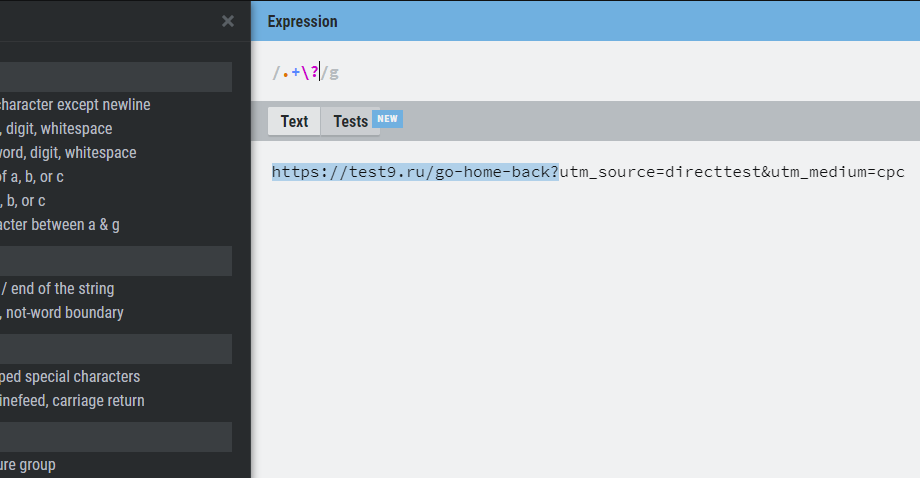
Поиск и замена части текста с помощью регулярных выражений
Быстрее и удобнее обрабатывать текст в гугл таблицах
В работе маркетолога часто приходится обрабатывать разнообразный по своему содержанию текст. При большом количестве элементов и их разной записи, делать это стандартными методами невозможно.
Для этого лучше использовать регулярные выражения.
Привожу шаблон Гугл таблиц с несколькими самыми популярными для аналитика запросами.
https://docs.google.com/spreadsheets/d/11IuUtQVZUFygTjNzZvaZepb_Y01rb1BT2EJSunD9vl0/edit?usp=sharing
Регулярные выражения
Регулярные выражения — это общепринятый большинством текстовых редакторов код, который означает тот или иной смысл. Например код .* означает все элементы.
Применение в google таблицах
Задачи могут сильно различаться. Например в гугл таблицах нужно убрать из utm ссылок всё, что идёт после адреса страницы.

Для этого нужно воспользоваться специальной формулой таблиц для регулярных выражений.
REGEXREPLACE(текст; регулярное_выражение; замена)
— С текстом всё понятно, выбираем ячейку с ссылкой;
— С регулярным выражением сложнее, пишем код \&.*|\?.* в отдельной ячейке и выбираю её. Далее разберу подробнее, что он значит;
— Для замены используем пустое место “”
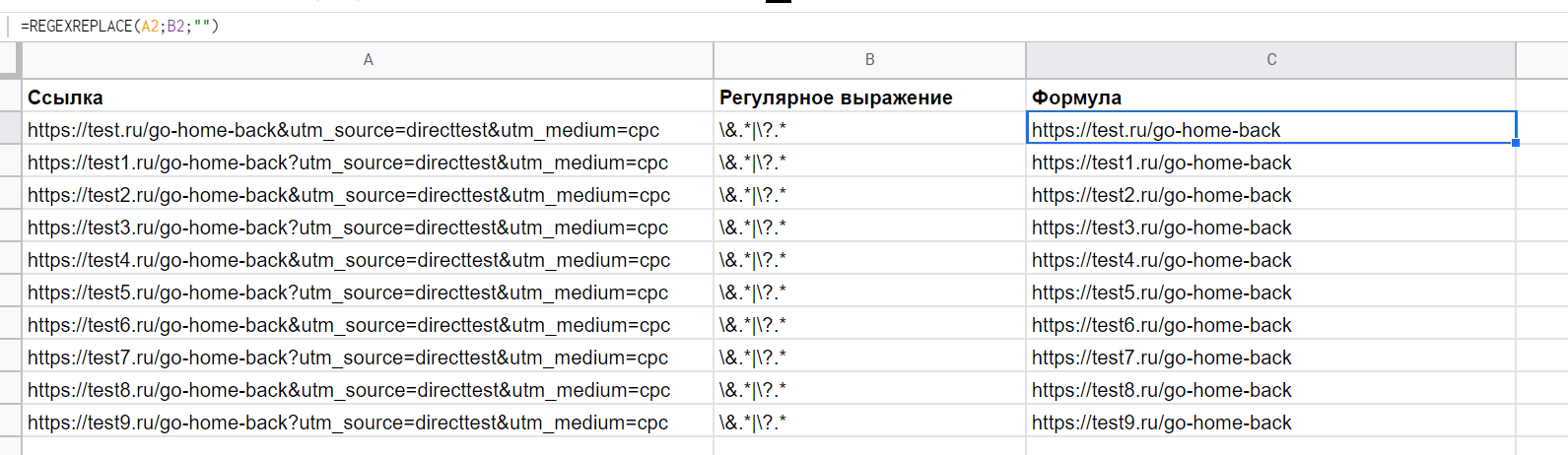
Получаем в столбце “Формула” ссылку без utm меток. Фактически происходит следующее:
Мы говорим, возьми текст из ячейки А2 → выбери по регулярному выражению в ячейке В2 весь текст из А2 → подставь пустое место (“”)
Разберём регулярное выражение \&.*|\?.*
Используя такой код, мы говорим возьми все символы (.*) до символа & (\&) или (|) возьми все символы (.*) до символа ? (\?)
Вывод с помощью регулярных выражений значений до символа с начала строки
Для этого нужно определить символ и вывести значения до него. Сделал пример в регулярных выражениях.

Разберём выражение
^[^\:]*
Где посмотреть все регулярные выражения
Значения регулярных выражений можно посмотреть на специальном сайте https://regexr.com/. Очень удобно вставить анализируемый текст и подбирать коды регулярных выражений. Подсветкой будет выделен выбираемый текст.
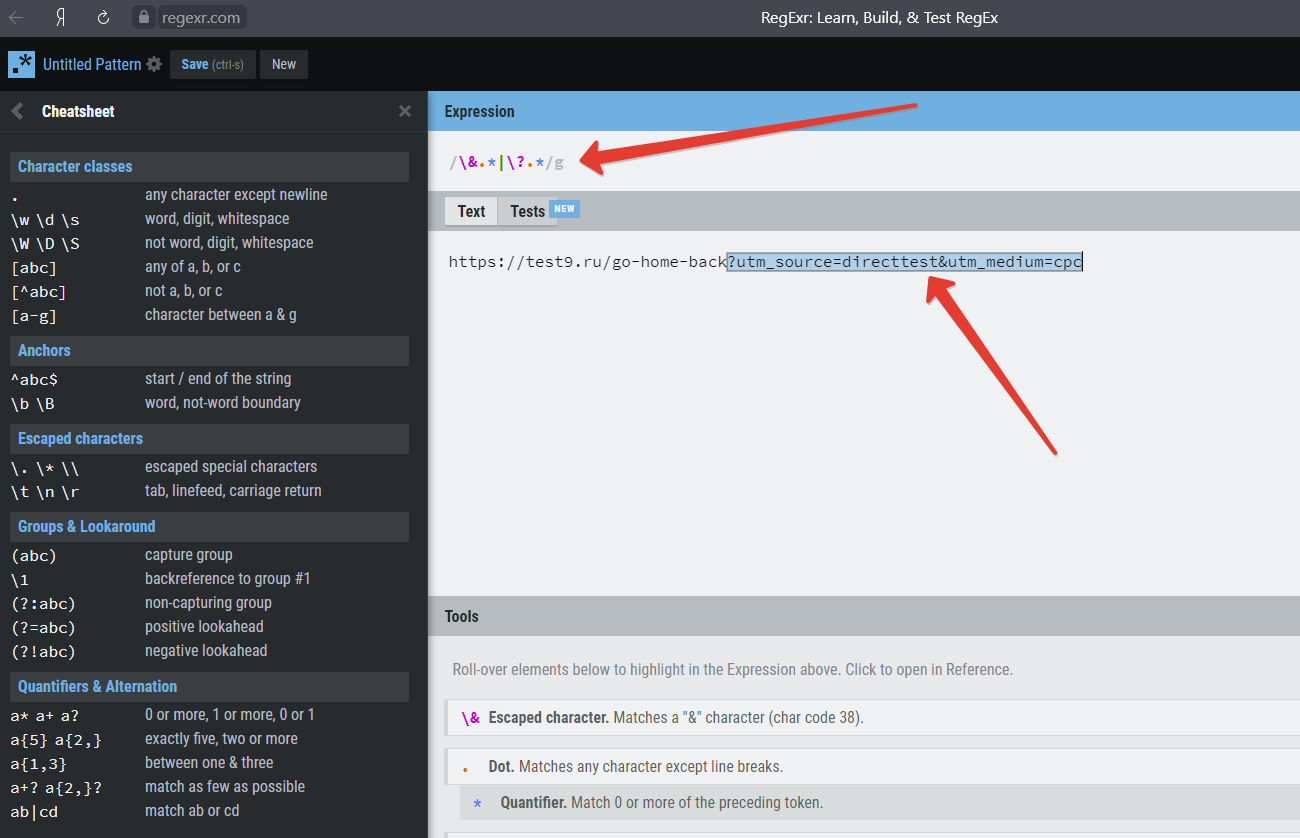
Коды приведены в левом пунтке меню Cheatsheet
Кратко привожу их тут
| Код | Описание |
| . | Самое простое – это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
| \s | Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
| \S | Анти-вариант предыдущего шаблона, т.е. любой НЕпробельный символ. |
| \d | Любая цифра |
| \D | Анти-вариант предыдущего, т.е. любая НЕ цифра |
| \w | Любой символ латиницы (A-Z), цифра или знак подчеркивания |
| \W | Анти-вариант предыдущего, т.е. не латиница, не цифра и не подчеркивание. |
| [символы] | В квадратных скобках можно указать один или несколько символов, разрешенных на указанной позиции в тексте. Например ст[уо]л будет соответствовать любому из слов: стол или стул. Также можно не перечислять символы, а задать их диапазоном через дефис, т.е. вместо [ABDCDEF] написать [A-F]. или вместо [4567] ввести [4-7]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] | Если после открывающей квадратной скобки добавить символ “крышки” ^, то набор приобретет обратный смысл – на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^ЖМ]уть найдет Путь или Суть или Забудь, но не Жуть или Муть, например. |
| | | Логический оператор ИЛИ (OR) для проверки по любому из указанных критериев. Например (счет|счёт|invoice) будет искать в тексте любое из указанных слов. Обычно набор вариантов заключается в скобки. |
| ^ | Начало строки |
| $ | Конец строки |
| \b | Край слова |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы – специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к тому символу, что стоит перед ним:
| Квантор | Описание |
| ? | Ноль или одно вхождение. Например .? будет означать один любой символ или его отсутствие. |
| + | Одно или более вхождений. Например \d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * | Ноль или более вхождений, т.е. любое количество. Так \s* означает любое количество пробелов или их отсутствие. |
| {число} или {число1,число2} | Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например \d{6} означает строго шесть цифр, а шаблон \s{2,5} – от двух до пяти пробелов |
Полезные ссылки по теме
Справка гугла
Помимо использования REGEXREPLACE регулярные выражения можно применять и вREGEXEXTRACT: Извлекает определенную часть текста, соответствующую регулярному выражению.REGEXMATCH: Проверяет, соответствует ли текст регулярному выражению.ПОДСТАВИТЬ: Заменяет один текст на другой.ЗАМЕНИТЬ: Заменяет выбранный текст на другой
Анализ текста регулярными выражениями (RegExp) в обычном Excel с помощью Visual
