
Программа обработки телефонов под единый стандарт на python
Пример кода программы для обработки телефонов под Яндекс Аудитории. Для работы вам потребуется установка python.
Проблема
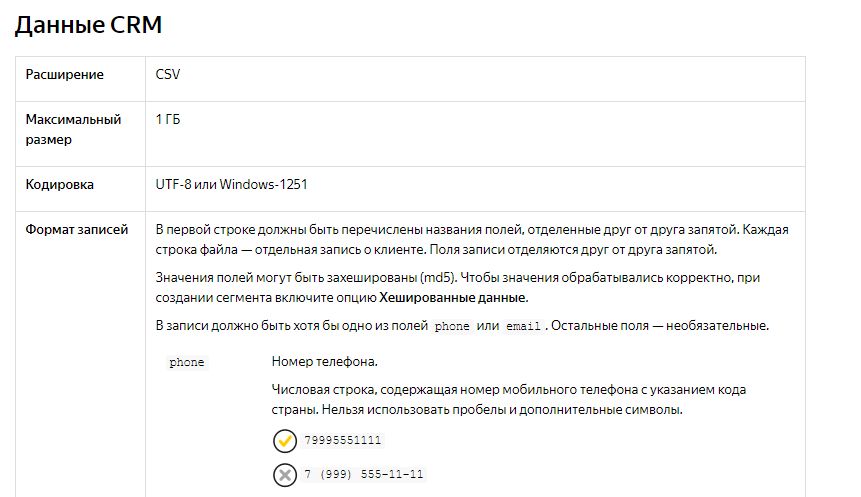
Чтобы создать сегмент аудиторий и последующую рекламу на похожих по данному сегменту пользователей с помощью look alike, нужно загрузить 1000 телефонов или email в интерфейс аудиторий. Проблема в том, что список телефонов, всегда в разнообразном виде.

Номера могут начинаться с 8 или +7, быть вовсе без начальных символов, содержать код города, иметь сторонние символы, типа пробелов, дифисов и т.д.
Но для Яндекс Аудиторий требуется привести всё к единому виду
Решение
Чтобы обработать сырой список контактов в несколько нажатий, я написал скрипт на python. Она работает так:
– Копируем на компьютере список телефонов,
– Открываем командную строку и запускаем программу,
– Копируем чистый список.
Всё!
Вот в три шага мы получаем готовый список. Копируем его в файл .csv и загружаем в Директ.
Пример
Копируем список из excel
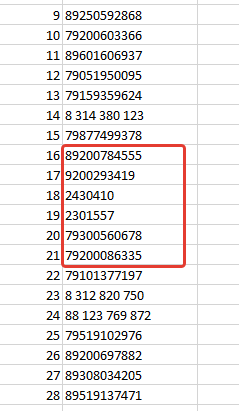
Запускаем программу, удаляем лишнее и получаем результат

Можно увидеть, что программа убрала некорректные номера. Теперь копирую нужные номера и вставляю куда нужно.
Код программы
import pyperclip
s = pyperclip.paste().split('\r\n')
s = pyperclip.paste().split('\r')
s = pyperclip.paste().split('\n')
def lower(data):
result = []
for row in data:
row = row.lower()
result.append(row)
return result
# Удаляю лишние символы
s2 = []
operation2 = input('Удалить все сторонние символы или какой-то один (,:"№ и т.д.)?: ')
if operation2 == ')':
for row in s:
row = row.replace(')', '')
#print(row)
if operation2 == '(':
for row in s:
row = row.replace('(', '')
#print(row)
if operation2 == '"':
for row in s:
row = row.replace('"', '')
#print(row)
if operation2 == '*':
for row in s:
row = row.replace('*', '')
#print(row)
if operation2 == ',':
for row in s:
row = row.replace(',', '')
#print(row)
if operation2 == '«':
for row in s:
row = row.replace('«', '')
#print(row)
if operation2 == '»':
for row in s:
row = row.replace('»', '')
#print(row)
if operation2 == '.':
for row in s:
row = row.replace('.', '')
#print(row)
if operation2 == "'":
for row in s:
row = row.replace("'", "")
#print(row)
if operation2 == "-":
for row in s:
row = row.replace("-", "")
#print(row)
if operation2 == " ":
for row in s:
row = row.replace(" ", "")
#print(row)
if operation2 == 'все' or operation2 == 'all' or operation2 == 'dct' or operation2 == 'Все':
for row in s:
row = row.replace('*', '')
row = row.replace(')', '')
row = row.replace('(', '')
row = row.replace('"', '')
row = row.replace('*', '')
row = row.replace('»', '')
row = row.replace('«', '')
row = row.replace(',', '')
row = row.replace('.', '')
row = row.replace("'", "")
row = row.replace("-", "")
row = row.replace(" ", "")
s2.append(row)
#print(row)
#print(s2) #проверяю всё ли заменилось нормально
#print(s2) #проверяю всё ли заменилось нормально
# Удаляю пустые ячейки и короткие телефоны без региона
s3 = []
for row in s2:
if len(row) > 9:
s3.append(row)
s4 = []
for row in s3:
if row != '':
s4.append(row)
#print(s4) #проверяю всё ли заменилось нормально
# Удаляю восьмерки в начале, меняю городские 88... на 78..., добавляю к 9... семерку вперёд 79...
for row in s4:
if row[0] == '8' and row[1] == '8':
print('7' + row[1:])
elif row[0] == '8' and row[1] != '8':
print('7' + row[1:])
elif row == '+':
print(row[1:])
elif row[0] == '9':
print('7' + row)
else:
print(row)